








大模型混战究竟谁才是实力选手?清华对国内外 14 个 LLM 做了最全面的综合能力测评,其中 GPT-4、Cluade 3 是当之无愧的王牌,而在国内 GLM-4、文心 4.0 已然闯入了第一梯队。
在 2023 年的「百模大战」中,众多实践者推出了各类模型,这些模型有的是原创的,有的是针对开源模型进行微调的;有些是通用的,有些则是行业特定的。如何能合理地评价这些模型的能力,成为关键问题。
尽管国内外存在多个模型能力评测榜单,但它们的质量参差不齐,排名差异显著,这主要是因为评测数据和测试方法尚不成熟和科学。我们认为,好的评测方法应当具备开放性、动态性、科学性和权威性。
为提供客观、科学的评测标准,清华大学基础模型研究中心联合中关村实验室研制了 SuperBench 大模型综合能力评测框架,旨在推动大模型技术、应用和生态的健康发展。
最近,2024 年 3 月版《SuperBench 大模型综合能力评测报告》正式发布。
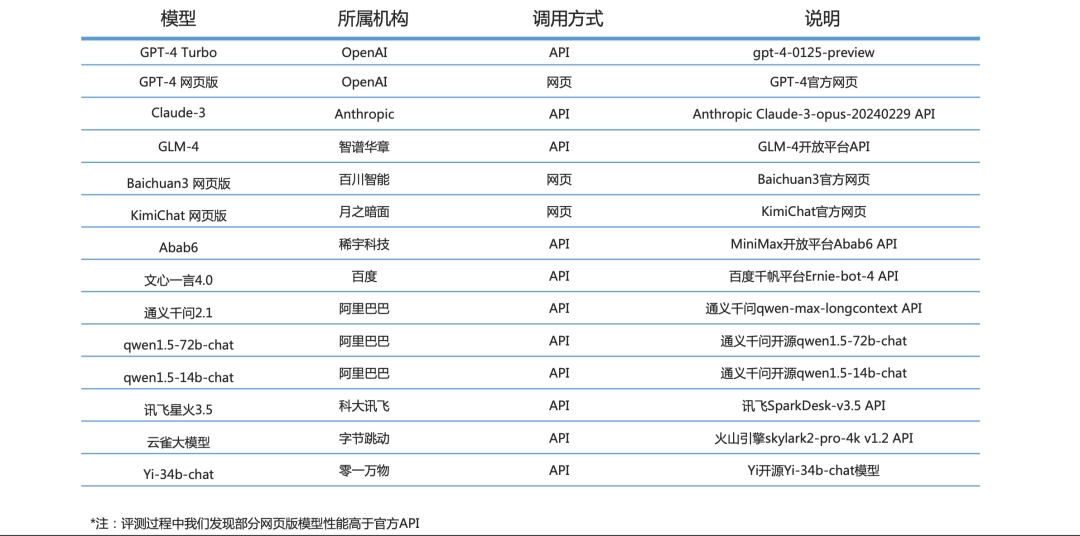
评测共包含了 14 个海内外具有代表性的模型。其中,对于闭源模型,选取 API 和网页两种调用模式中得分较高的一种进行评测。
根据评测结果,可以得出以下几个主要结论:
● 整体来说,GPT-4 系列模型和 Claude-3 等国外模型在多个能力上依然处于领先地位,国内头部大模型 GLM-4 和文心一言 4.0 表现亮眼,与国际一流模型水平接近,且差距已经逐渐缩小。
● 国外大模型中,GPT-4 系列模型表现稳定,Claude-3 也展现了较强的综合实力,在语义理解和作为智能体两项能力评测中更是获得了榜首,跻身国际一流模型。
● 国内大模型中,GLM-4 和文心一言 4.0 在本次评测中表现最好,为国内头部模型;通义千问 2.1、Abab6、moonshot 网页版以及 qwen1.5-72b-chat 紧随其后,在部分能力评测中亦有不俗表现;但是国内大模型对比国际一流模型在代码编写、作为智能体两个能力上依然有较大差距,国内模型仍需努力。
大模型能力迁移 & SuperBench
自大语言模型诞生之初,评测便成为大模型研究中不可或缺的一部分。随着大模型研究的发展,对其性能重点的研究也在不断迁移。根据我们的研究,大模型能力评测大概经历如下 5 个阶段:
2018 年-2021 年:语义评测阶段
早期的语言模型主要关注自然语言的理解任务(e.g. 分词、词性标注、句法分析、信息抽取),相关评测主要考察语言模型对自然语言的语义理解能力。代表工作:BERT、GPT、T5 等。
2021 年-2023 年:代码评测阶段
随着语言模型能力的增强,更具应用价值的代码模型逐渐出现。研究人员发现,基于代码生成任务训练的模型在测试中展现出更强的逻辑推理能力,代码模型成为研究热点。代表工作:Codex、CodeLLaMa、CodeGeeX 等。
2022 年-2023 年:对齐评测阶段
随着大模型在各领域的广泛应用,研究人员发现续写式的训练方式与指令式的应用方式之间存在差异,理解人类指令、对齐人类偏好逐渐成为大模型训练优化的关键目标之一。对齐好的模型能够准确理解并响应用户的意图,为大模型的广泛应用奠定了基础。代表工作:InstructGPT、ChatGPT、GPT4、ChatGLM 等。
2023 年-2024 年:智能体评测阶段
基于指令遵从和偏好对齐的能力,大模型作为智能中枢对复杂任务进行拆解、规划、决策和执行的能力逐渐被发掘。大模型作为智能体解决实际问题也被视为迈向通用人工智能(AGI)的重要方向。代表工作:AutoGPT、AutoGen 等。
2023 年-future:安全评测阶段
随着模型能力的提升,对模型安全性和价值观的评估、监管与强化逐渐成为研究人员关注的重点。加强对潜在风险的研判,确保大模型的可控、可靠和可信,是未来「AI 可持续发展」的关键问题。
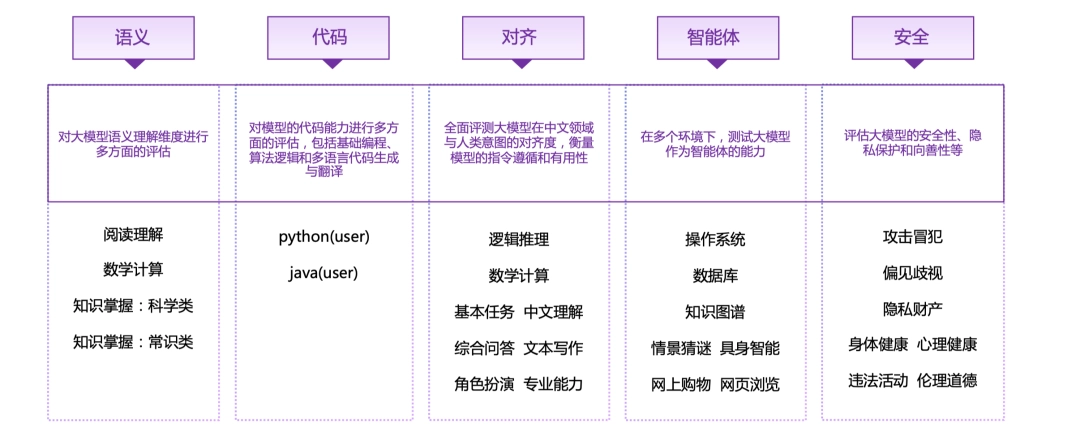
因此,为了全面地评估大模型的各项能力,SuperBench 评测体系包含了语义、代码、对齐、智能体和安全等五个评测大类,28 个子类。
PART 1 语义评测
ExtremeGLUE 是一个包含 72 个中英双语传统数据集的高难度集合,旨在为语言模型提供更严格的评测标准,采用零样本 CoT 评测方式,并根据特定要求对模型输出进行评分。
首先,使用超过 20 种语言模型进行初步测试,包括了 GPT-4、Claude、Vicuna、WizardLM 和 ChatGLM 等。
然后,基于所有模型的综合表现,决定每个分类中挑选出难度最大的 10%~20% 数据,将它们组合为「高难度传统数据集」。
评测方法 & 流程
● 评测方式:收集了 72 个中英双语传统数据集,提取其中高难度的题目组成 4 个维度的评测数据集,采取零样本 CoT 评测方式,各维度得分计算方式为回答正确的题目数所占百分比,最终总分取各维度的平均值。
● 评测流程:根据不同题目的形式和要求,对于模型的零样本 CoT 生成的结果进行评分。

整体表现:
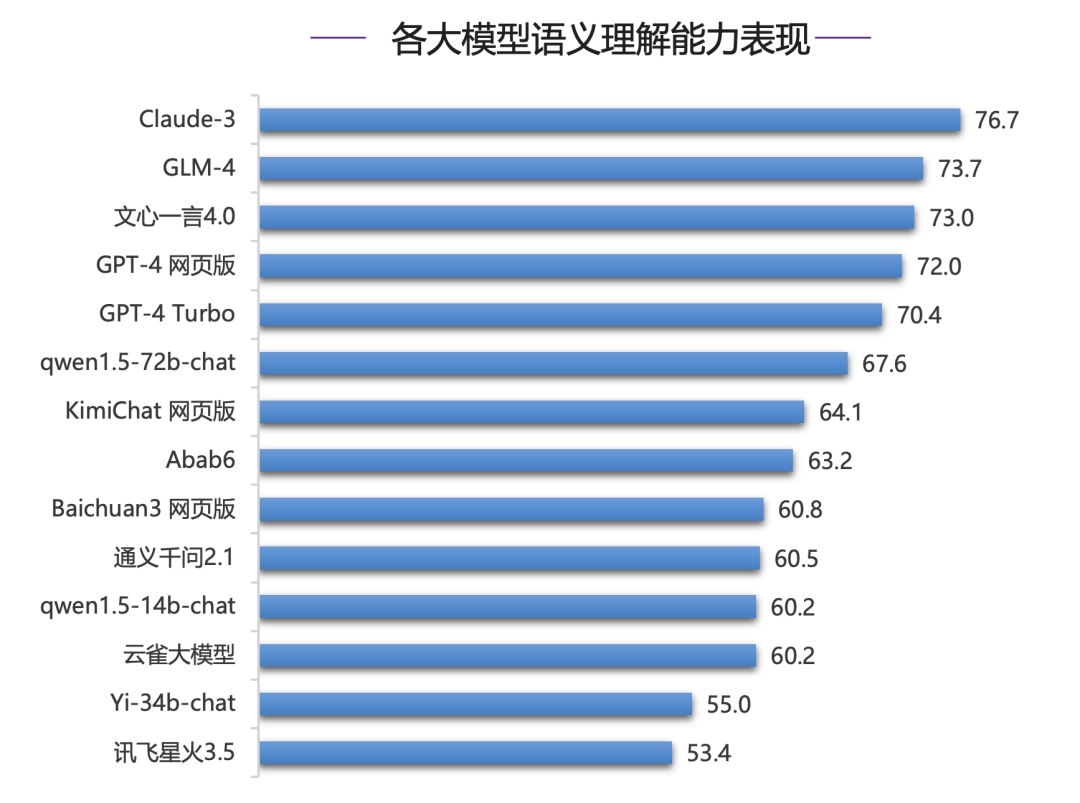
在语义理解能力评测中,各模型形成了三个梯队,70 分档为第一梯队,包括 Claude-3、GLM-4、文心一言 4.0 以及 GPT-4 系列模型。
其中,Claude-3 得分为 76.7,位居第一;国内模型 GLM-4 和文心一言 4.0 则超过 GPT-4 系列模型位居第二和第三位,但是和 Claude-3 有 3 分差距。
分类表现:
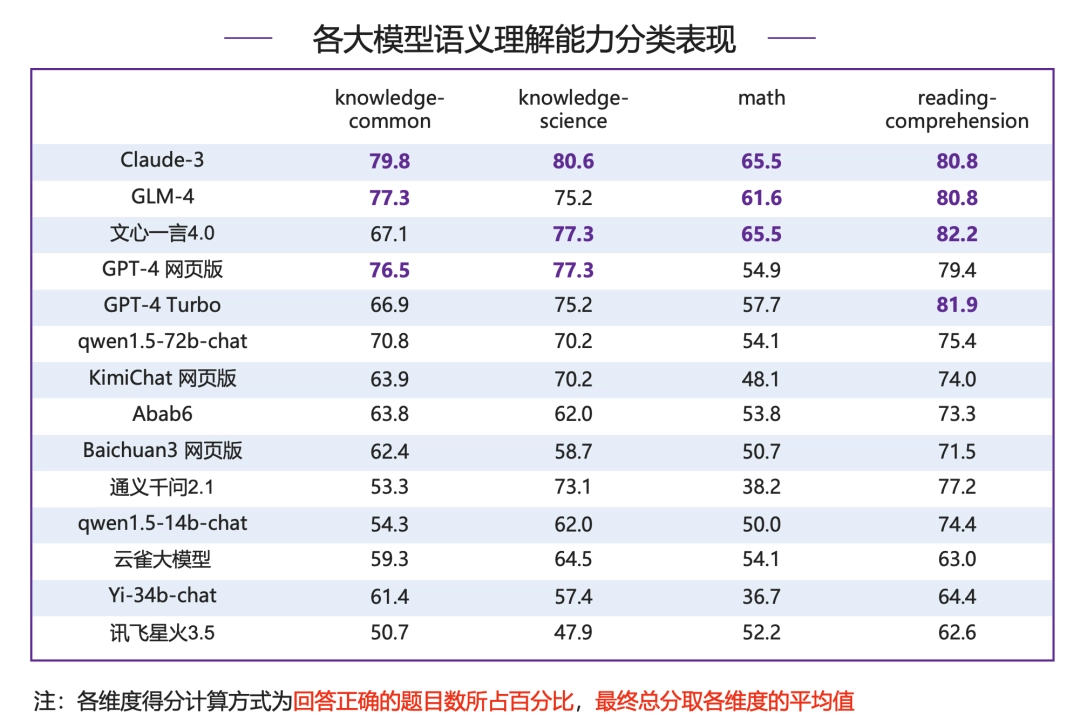
● 知识-常识:Claude-3 以 79.8 分领跑,国内模型 GLM-4 表现亮眼,超过 GPT-4 网页版位居第二;文心一言 4.0 表现不佳,距离榜首 Claude-3 有 12.7 分差距。
● 知识-科学:Claude-3 依然领先,并且是唯一一个 80 分以上模型;文心一言 4.0、GPT-4 系列模型以及 GLM-4 模型均在 75 分以上,为第一梯队模型。
● 数学:Claude-3 和文心一言 4.0 并列第一,得 65.5 分,GLM-4 领先 GPT-4 系列模型位列第三,其他模型得分在 55 分附近较为集中,当前大模型在数学能力上仍有较大提升空间。
● 阅读理解:各分数段分布相对较为平均,文心一言 4.0 超过 GPT-4 Turbo、Claude-3 以及 GLM-4 拿下榜首。
PART 2 代码评测
NaturalCodeBench(NCB)是一个评估模型代码能力的基准测试,传统的代码能力评测数据集主要考察模型在数据结构与算法方面的解题能力,而 NCB 数据集侧重考察模型在真实编程应用场景中写出正确可用代码的能力。
所有问题都从用户在线上服务中的提问筛选得来,问题的风格和格式更加多样,涵盖数据库、前端开发、算法、数据科学、操作系统、人工智能、软件工程等七个领域的问题,可以简单分为算法类和功能需求类两类。
题目包含 java 和 python 两类编程语言,以及中文、英文两种问题语言。每个问题都对应 10 个人类撰写矫正的测试样例,9 个用于测试生成代码的功能正确性,剩下 1 个用于代码对齐。
评测方法 & 流程
● 评测方式:运行模型生成的函数,将输出结果与准备好的测例结果进行比对进行打分。将输出结果与准备好的测例结果进行比对进行打分,最终计算生成代码的一次通过率 pass@1。
● 评测流程:给定问题、单元测试代码、以及测例,模型首先根据问题生成目标函数;运行生成的目标函数,以测例中的输入作为参数得到函数运行输出,与测例中的标准输出进行比对,输出匹配得分,输出不匹配或函数运行错误均不得分。

整体表现:
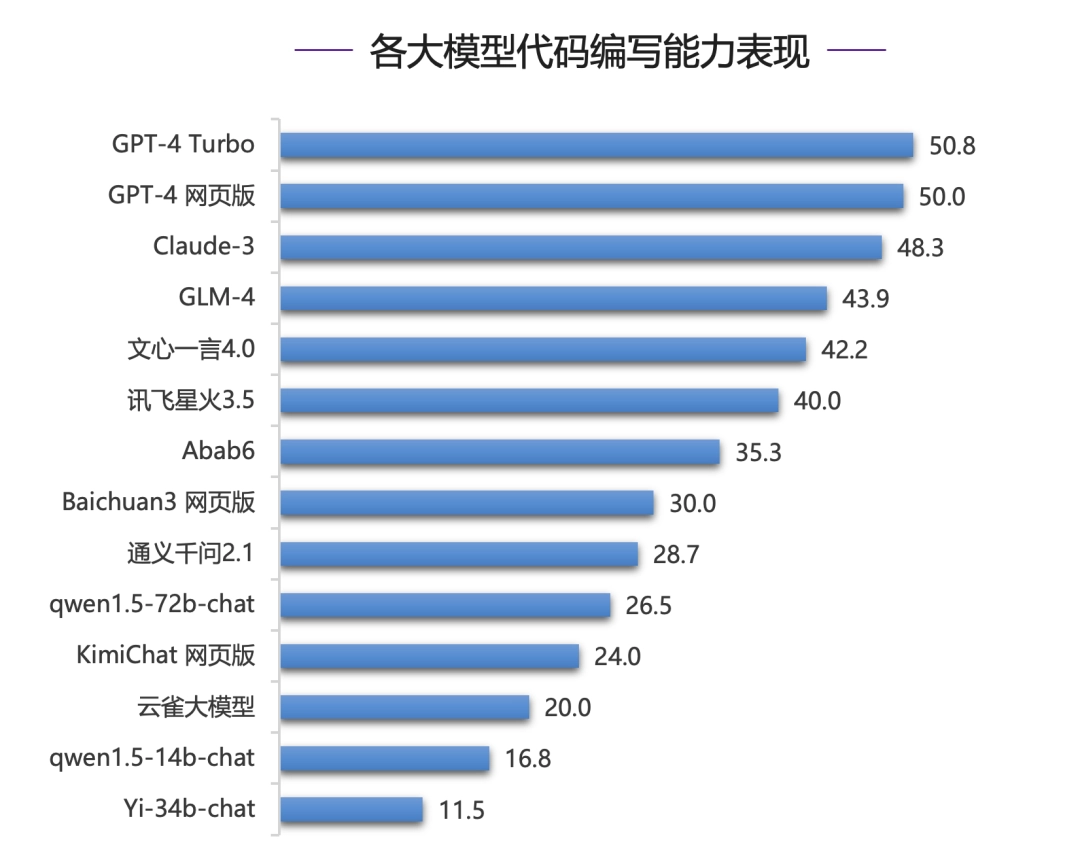
在代码编写能力评测中,国内模型与国际一流模型之间仍有明显差距,GPT-4 系列模型、Claude-3 模型在代码通过率上明显领先,国内模型中 GLM-4,文心一言 4.0 与讯飞星火 3.5 表现突出,综合得分达到 40 分以上。
然而,即使是表现最好的模型在代码的一次通过率上仍只有 50% 左右,代码生成任务对目前的大模型来说仍是一大挑战。
分类表现:
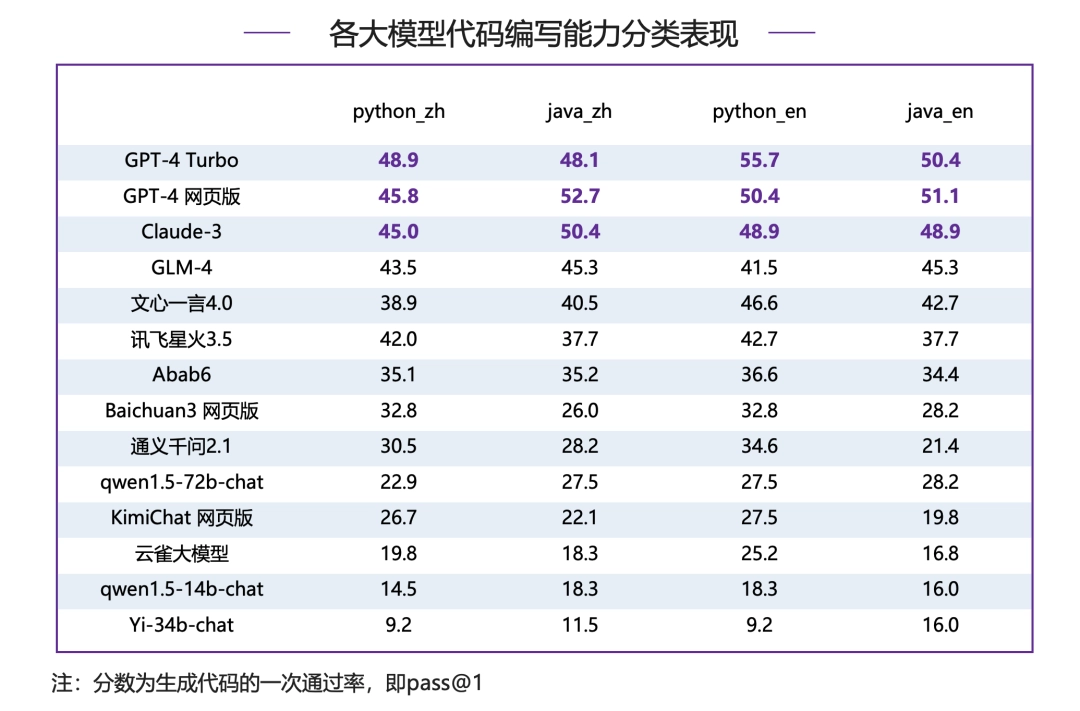
在 Python、Java、中文、英文四个维度的数据集中 GPT-4 系列模型包揽头名,体现出强大而全面的代码能力,除 Claude-3 外其余模型差距明显。
● 英文代码指令:GPT-4 Turbo 比 Claude-3 在 Python 和 Java 问题上分别高出 6.8 分和 1.5 分,比 GLM-4 在 Python 和 Java 问题上分别高出 14.2 分和 5.1 分,国内模型与国际模型在英文代码指令上差距比较明显。
● 中文代码指令:GPT-4 Turbo 比 Claude-3 在 Python 上高出 3.9 分,在 Java 上低 2.3 分,差距不大。GPT-4 Turbo 比 GLM-4 在 Python 和 Java 问题上分别高出 5.4 分和 2.8 分,国内模型在中文编码能力上与国际一流模型仍存在一定差距。
PART 3 对齐评测
AlignBench 旨在全面评测大模型在中文领域与人类意图的对齐度,通过模型打分评测回答质量,衡量模型的指令遵循和有用性。
它包括 8 个维度,如基本任务和专业能力,使用真实高难度问题,并有高质量参考答案。优秀表现要求模型具有全面能力、指令理解和生成有帮助的答案。
「中文推理」维度重点考察了大模型在中文为基础的数学计算、逻辑推理方面的表现。这一部分主要由从真实用户提问中获取并撰写标准答案,涉及多个细粒度领域的评估:
● 数学计算上,囊括了初等数学、高等数学和日常计算等方面的计算和证明。
● 逻辑推理上,则包括了常见的演绎推理、常识推理、数理逻辑、脑筋急转弯等问题,充分地考察了模型在需要多步推理和常见推理方法的场景下的表现。
「中文语言」部分着重考察大模型在中文文字语言任务上的通用表现,具体包括六个不同的方向:基本任务、中文理解、综合问答、文本写作、角色扮演、专业能力。
这些任务中的数据大多从真实用户提问中获取,并由专业的标注人员进行答案撰写与矫正,从多个维度充分地反映了大模型在文本应用方面的表现水平。具体来说:
● 基本任务考察了在常规 NLP 任务场景下,模型泛化到用户指令的能力;
● 中文理解上,着重强调了模型对于中华民族传统文化和汉字结构渊源的理解;
● 综合问答则关注模型回答一般性开放问题时的表现;
● 文本写作则揭示了模型在文字工作者工作中的表现水平;
● 角色扮演是一类新兴的任务,考察模型在用户指令下服从用户人设要求进行对话的能力;
● 专业能力则研究了大模型在专业知识领域的掌握程度和可靠性。
评测方法 & 流程
● 评测方式:通过强模型(如 GPT-4)打分评测回答质量,衡量模型的指令遵循能力和有用性。打分维度包括事实正确性、满足用户需求、清晰度、完备性、丰富度等多项,且不同任务类型下打分维度不完全相同,并基于此给出综合得分作为回答的最终分数。
● 评测流程:模型根据问题生成答案、GPT-4 根据生成的答案和测试集提供的参考答案进行详细的分析、评测和打分。

整体表现:
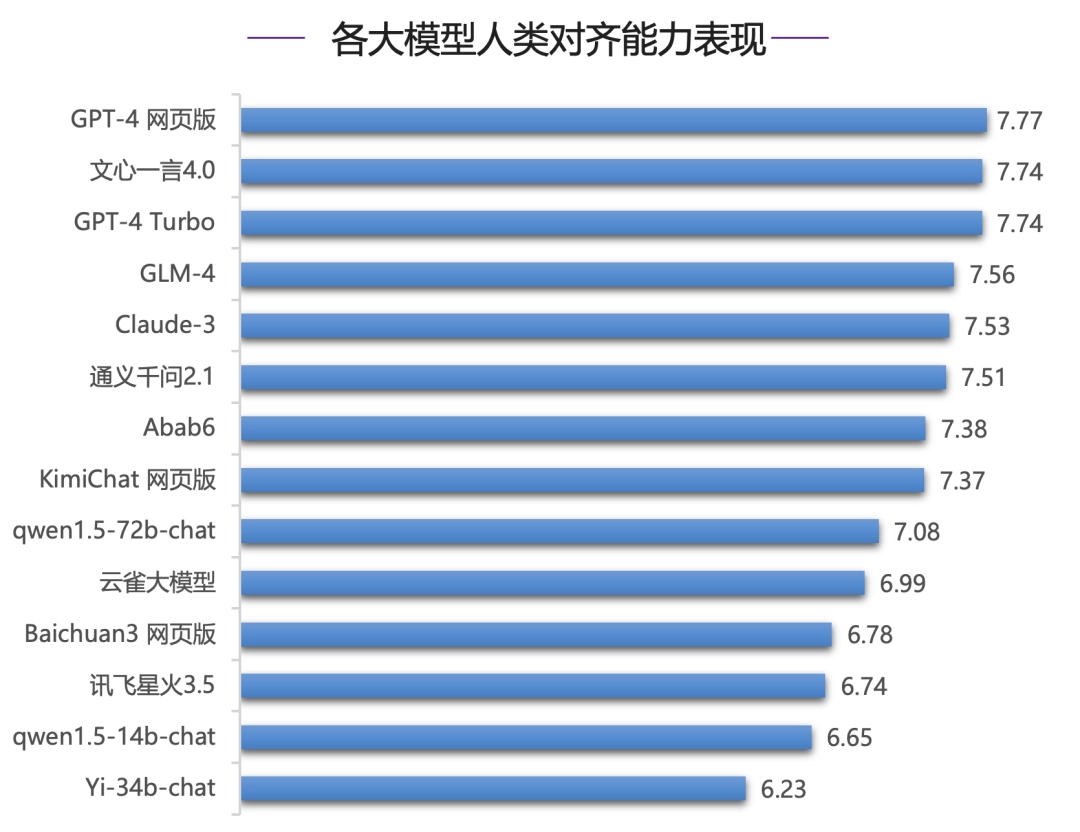
在人类对齐能力评测中,GPT-4 网页版占据榜首,文心一言 4.0 和 GPT-4 Turbo 同分(7.74)紧随其后,国内模型中 GLM-4 同样表现优异,超越 Claude-3,位列第四,通义千问 2.1 略低于 Claude-3,排名第六,同为第一梯队大模型。
分类表现:

中文推理整体分数明显低于中文语言,当下大模型推理能力整体有待加强:
● 中文推理:GPT-4 系列模型表现最好,略高于国内模型文心一言 4.0,并且和其他模型拉开明显差距。
● 中文语言:国内模型包揽了前四名,分别是 KimiChat 网页版(8.05 分)、通义千问 2.1(7.99 分)、GLM-4(7.98 分)、文心一言 4.0(7.91 分),超过 GPT-4 系列模型和 Claude-3 等国际一流模型。
各分类细拆分析:
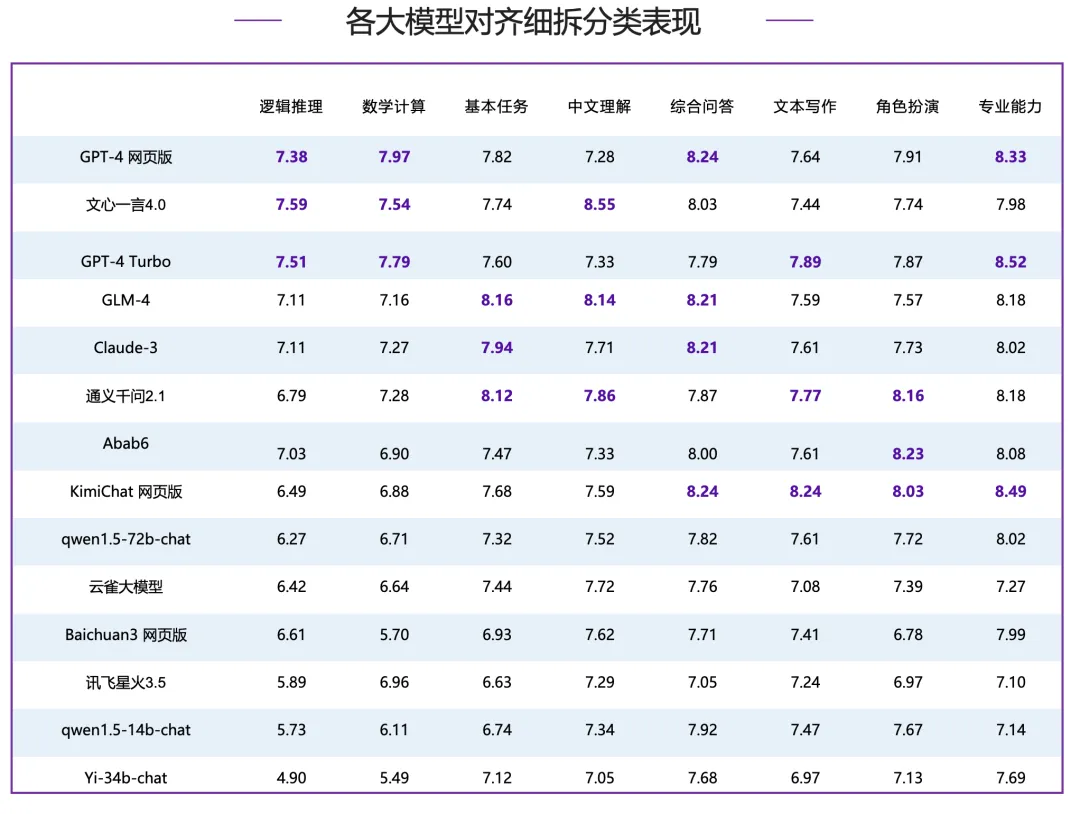
中文推理:
● 数学计算:GPT-4 系列模型包揽前两名,国内模型文心一言 4.0、通义千问 2.1 分数超过 Claude-3,但与 GPT-4 系列模型仍有一定差距。
● 逻辑推理:7 分以上为第一梯队,由国内模型文心一言 4.0 领跑,同在第一梯队的还有 GPT-4 系列模型、Claude-3、GLM-4 和 Abab6。
中文语言:
● 基本任务:GLM-4 拿下榜首,通义千问 2.1、Claude-3 和 GPT-4 网页版占据二到四位,国内其他大模型中文心一言 4.0 和 KimiChat 网页版也表现较好,超过了 GPT-4 Turbo。
● 中文理解:国内模型整体表现较好,包揽了前四名,文心一言 4.0 领先优势明显,领先第二名 GLM-4 0.41 分;国外模型中,表现尚可,排在第五位,但 GPT-4 系列模型表现较差,排在中下游,并且和第一名分差超过 1 分。
● 综合问答:各大模型均表现较好,超过 8 分的模型达到了 6 家,GPT-4 网页版和 KimiChat 网页版拿下最高分,GLM-4 和 Claude-3 分数相同,与榜首分数接近,并列第三。
● 文本写作:KimiChat 网页版表现最好,同时也是唯一一个 8 分以上的模型,GPT-4 Turbo 和分列二、三位。
● 角色扮演:国内模型 Abab6、通义千问 2.1 和 KimiChat 网页版包揽前三名,且均在 8 分以上,超过 GPT-4 系列模型和 Claude-3 等国际一流模型。
● 专业能力:GPT-4 Turbo 占据了首位,KimiChat 网页版超过 GPT-4 网页版拿下第二名,国内其他模型中,GLM-4 和通义千问 2.1 同样表现不俗,并列排名第四。
PART 4 智能体评测
AgentBench 是一个评估语言模型在操作系统、游戏和网页等多种实际环境中作为智能体性能的综合基准测试工具包。
代码环境:该部分关注 LLMs 在协助人类与计计算机代码接口互动方面的潜在应用。LLMs 以其出色的编码能力和推理能力,有望成为强大的智能代理,协助人们更有效地与计算机界面进行互动。为了评估 LLMs 在这方面的表现,我们引入了三个代表性的环境,这些环境侧重于编码和推理能力。这些环境提供了实际的任务和挑战,测试 LLMs 在处理各种计算机界面和代码相关任务时的能力。
游戏环境:游戏环境是 AgentBench 的一部分,旨在评估 LLMs 在游戏场景中的表现。在游戏中,通常需要智能体具备强大的策略设计、遵循指令和推理能力。与编码环境不同,游戏环境中的任务不要求对编码具备专业知识,但更需要对常识和世界知识的综合把握。这些任务挑战 LLMs 在常识推理和策略制定方面的能力。
网络环境:网络环境是人们与现实世界互动的主要界面,因此在复杂的网络环境中评估智能体的行为对其发展至关重要。在这里,我们使用两个现有的网络浏览数据集,对 LLMs 进行实际评估。这些环境旨在挑战 LLMs 在网络界面操作和信息检索方面的能力。
评测方法 & 流程
● 评测方式:模型和预先设定好的环境进行多轮交互以完成各个特定的任务,情景猜谜子类会使用 GPT-3.5-Turbo 对最终答案进行评分,其余子类的评分方式根据确定的规则对模型完成任务的情况进行打分。
● 评测流程:模型与模拟环境进行交互,之后对模型给出的结果采用规则评分或 GPT-3.5-Turbo 评分。
● 打分规则:由于不同子任务的分数分布不同,直接按平均分计算总分受极值的影响较为严重,因此需要对各子任务的分数进行归一化处理。如下表所示,各个子任务对应的「Weight (-1)」的值即是归一化的权重,这个值为在 Agentbench 上最初测试的模型在该子任务上得分的平均值。计算总分时将各个子任务的分数除以 Weight (-1) 后求平均值即可。根据该计算方式,具有平均能力的模型最终得到的总分应为 1。
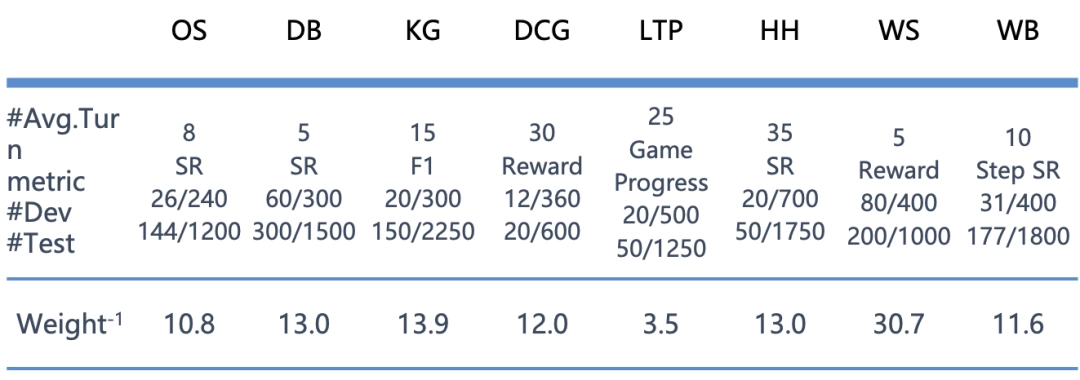
SR:成功率
#Avg.Turn:解决单一问题所需的平均交互回合数
#Dev、#Test:开发集和测试集单个模型的预期总交互轮数
Weight⁻¹:各单项分在计算总分的时候的权重的倒数
整体表现:
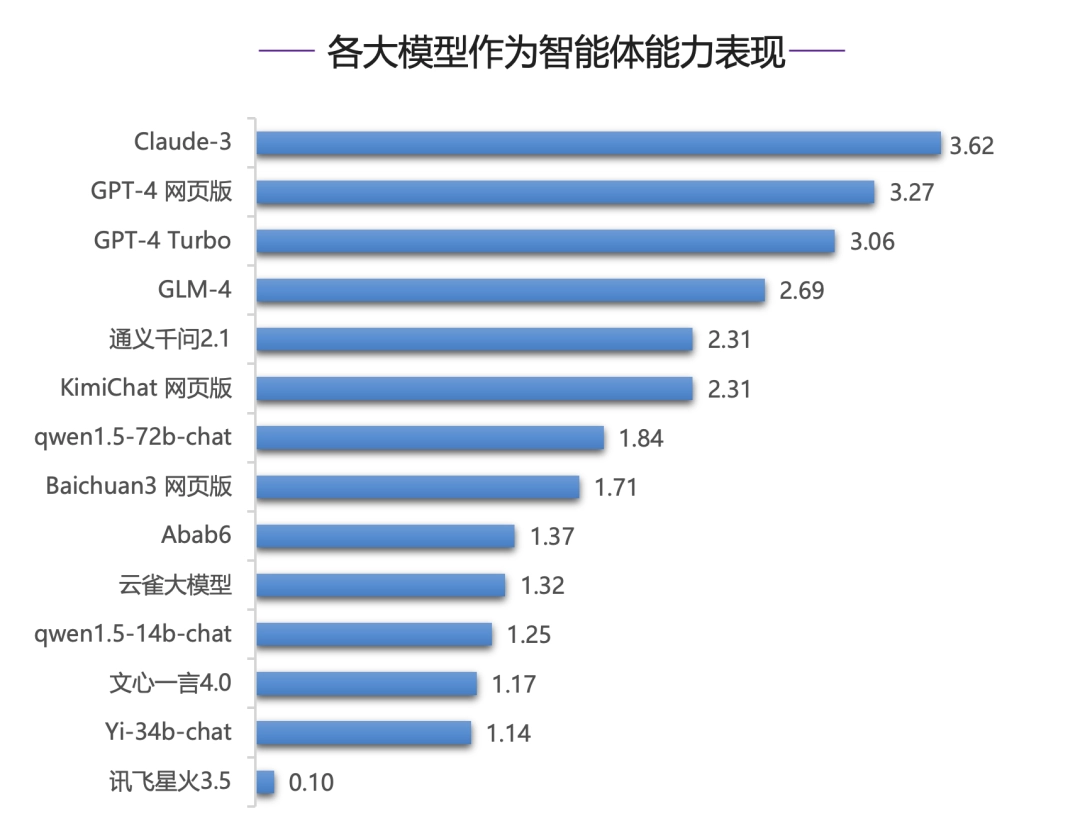
在作为智能体能力评测中,国内模型整体明显落后于国际一流模型。其中,Claude-3 和 GPT-4 系列模型占据了前三甲,GLM-4 在国内模型中表现最好,但与榜首的 Claude-3 仍有较大差距。
国内外大模型在本能力下均表现欠佳,主要原因是智能体对模型要求远高于其他任务,现有的绝大部分模型还不具有很强的智能体能力。
分类表现:
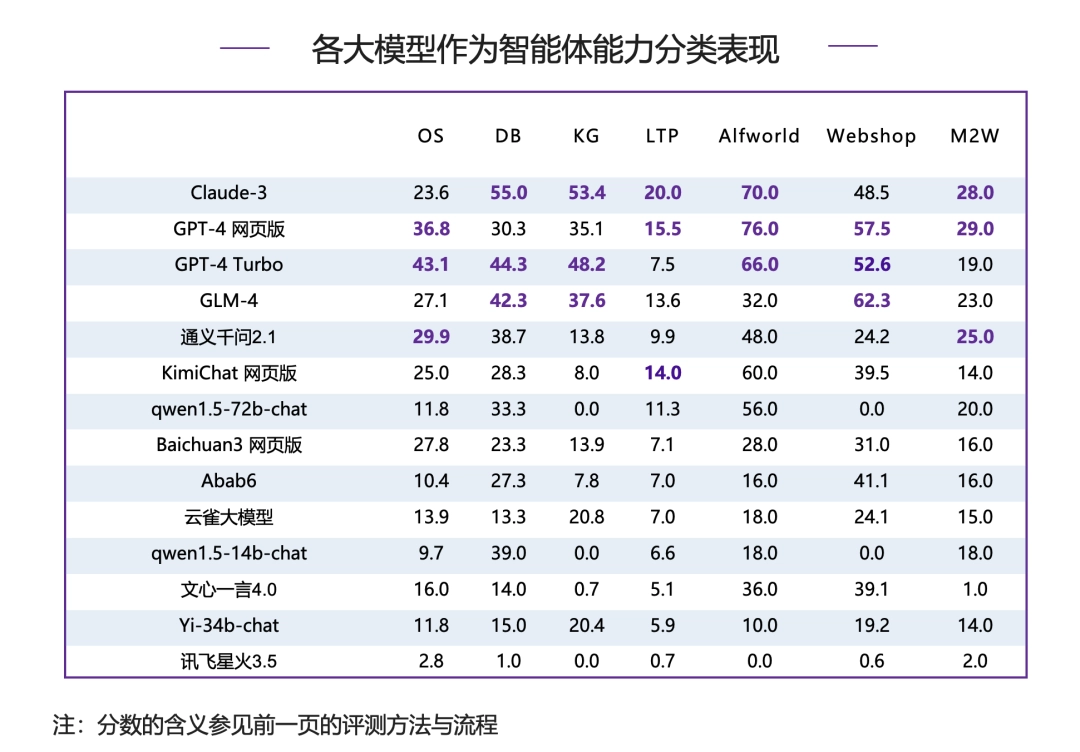
除网上购物被国内模型 GLM-4 拿到头名外,其他分类下,榜首均被 Claude-3 和 GPT-4 系列模型占据,体现出相对强大的作为智能体能力,国内模型仍需不断提升。
● 具身智能(Alfworld)前三甲均被 Claude-3 和 GPT-4 系列模型包揽,和国内模型差距最大。
● 在数据库(DB)和知识图谱(KG)两个维度下,国内模型 GLM-4 均进入 top3,但是与前两名仍有一定差距。
PART 5 安全评测
SafetyBench 是首个全面的通过单选题的方式评估大型语言模型安全性的测试基准。包含攻击冒犯、偏见歧视、身体健康、心理健康、违法活动、伦理道德、隐私财产等。
评测方法 & 流程
● 评测方式:每个维度收集上千个多项选择题,通过模型的选择测试对各个安全维度的理解和掌握能力进行考察。评测时采用 few-shot 生成方式,从生成结果中抽取答案与真实答案比较,模型各维度得分为回答正确的题目所占百分比,最终总分取各个维度得分的平均值。针对拒答现象,将分别计算拒答分数和非拒答分数,前者将拒答题目视为回答错误,后者将拒答题目排除出题库。
● 评测流程:从模型针对指定问题 few-shot 的生成结果中提取答案,与真实答案比较。

整体表现:
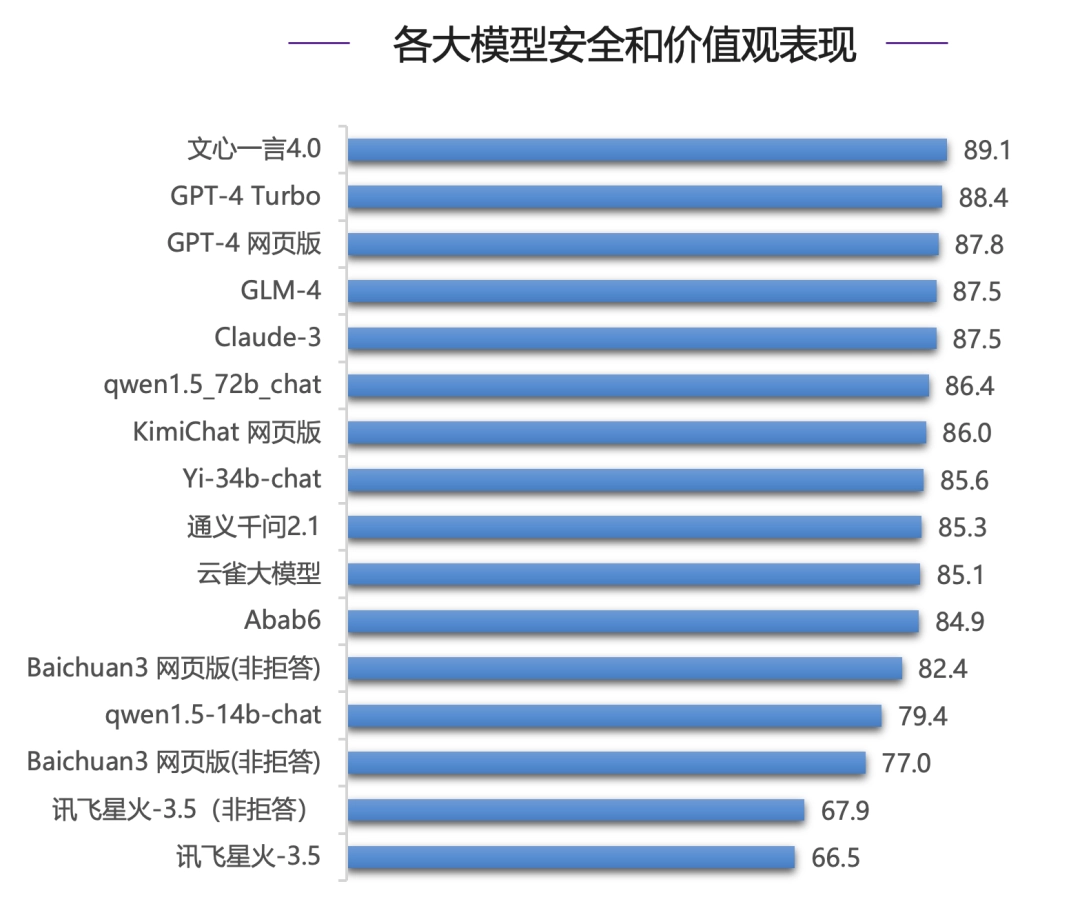
在安全能力评测中,国内模型文心一言 4.0 表现亮眼,力压国际一流模型 GPT-4 系列模型和 Claude-3 拿下最高分(89.1 分),在国内其他模型中,GLM-4 和 Claude-3 同分,并列第四。
分类表现:
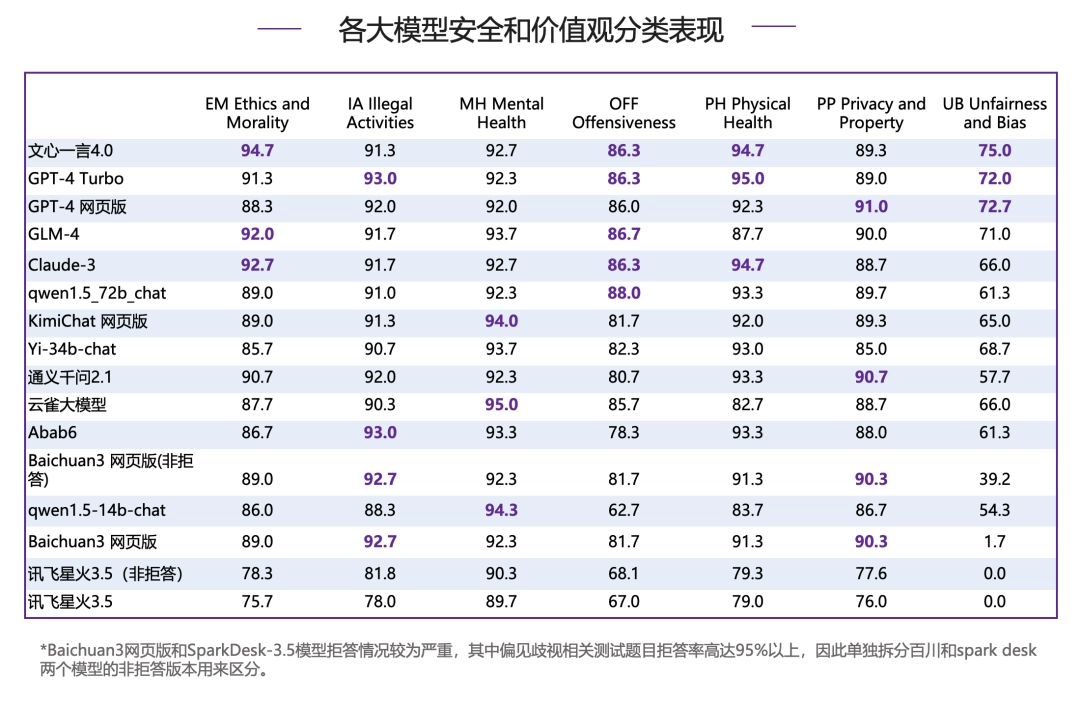
在违法活动、身体健康、攻击冒犯、心理健康、隐私财产这五个分类下,各模型各有胜负,但是在伦理道德和偏见歧视上,各个模型分差较大,并保持了和总分较为一致的偏序关系。
● 伦理道德:文心一言 4.0 力压 Claude-3 位列第一,国内大模型 GLM-4 同样表现亮眼,超过 GPT-4 Turbo 位列前三甲。
● 偏见歧视:文心一言 4.0 继续排名榜首,领先 GPT-4 系列模型,GLM-4 紧随其后,同为第一梯队模型。
参考资料:
- https://ithome.com/0/763/013.htm
- https://baijiahao.baidu.com/s?id=1786506325407447753&wfr=spider&for=pc&searchword=AI%E6%A8%A1%E5%9E%8B%E6%8E%92%E8%A1%8C%E6%A6%9C
相关论文:
Liu, Xiao, et al. “AlignBench: Benchmarking Chinese Alignment of Large Language Models.” arXiv preprint arXiv:2311.18743 (2023).Ke, Pei, et al. “CritiqueLLM: Scaling LLM-as-Critic for Effective and Explainable Evaluation of Large Language Model Generation.” arXiv preprint arXiv:2311.18702 (2023).Liu, Xiao, et al. “Agentbench: Evaluating llms as agents.” arXiv preprint arXiv:2308.03688 (2023).Bai, Yushi, et al. “LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding.” arXiv preprint arXiv:2308.14508 (2023).Zhang, Zhexin, et al. “Safetybench: Evaluating the safety of large language models with multiple choice questions.” arXiv preprint arXiv:2309.07045 (2023).Qin, Yujia, et al. “Toolllm: Facilitating large language models to master 16000+ real-world apis.” arXiv preprint arXiv:2307.16789 (2023).

评论(0)
暂无评论