二、“优雅地”认识各类AI知识库问答系统、构建 AI 应用程序平台
在上一篇文章中:如何“优雅地”本地部署Deepseek?——(Ollama for Windows) – 辰汐の小站我们已经搭建好了本地大模型,但是这个的缺陷是我们只能在命令行cmd中进行对话,操作界面“不优雅”之外还有着诸多不便;本文将从本地部署可视化界面开始说起~
一、什么是AI知识库问答系统、构建 AI 应用程序平台?
(一)简介
AI 知识库问答系统,简单来说,就是一种能够理解用户以自然语言提出的问题,并从预先构建的知识库(可以是你给AI的各类知识)中提取相关信息,进而生成准确答案的智能系统。它就像是一个随时待命、无所不知的智能助手,能够跨越语言的障碍,直接与用户进行自然流畅的交流。当你向它提问时,它会迅速对问题进行分析和理解,然后在庞大的知识储备中精准定位,找到最相关的信息,并以清晰易懂的语言反馈给使用这个AI应用的人。
在日常生活中,我们经常能接触到 AI 知识库问答系统的应用。电商平台的智能客服就是一个典型的例子。当你在网上购物时,遇到诸如商品信息咨询、物流查询、售后服务等问题,只需向智能客服提问,它就能快速给出准确的回答。像你询问某款手机的配置参数、颜色款式,或者查询订单的发货进度,智能客服都能迅速响应,为你提供所需的信息(这是因为店家已经将各个手机的相关配置提前通过构建知识库告诉给了AI)。智能语音助手,如苹果的 Siri、小米的小爱同学等,也是 AI 知识库问答系统的一种体现。你可以通过语音与它们交流,让它们帮你查询天气、设置提醒、播放音乐,甚至进行知识问答,它们都能根据你的指令,从知识库中获取信息并完成相应的任务 ,给我们的生活带来了极大的便利。
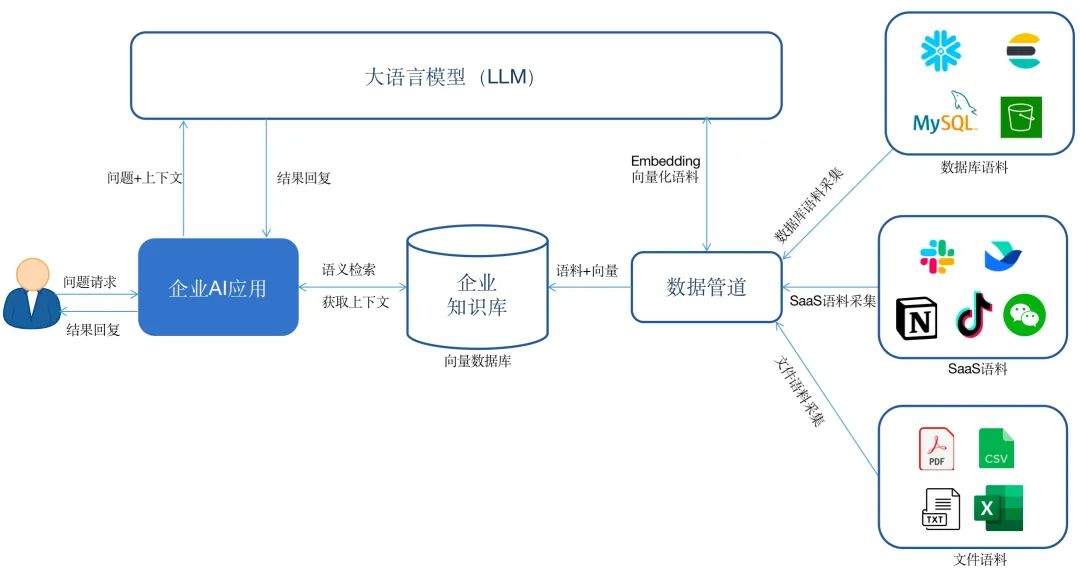
再简单来说,知识库相当于是一个给AI看的字典,当用户问及字典内的相关内容时,AI会自动检索字典中的信息,告诉给用户
(二)核心技术与工作原理(想了解的可以看看~)
- 1.自然语言处理(NLP):NLP 技术是 AI 知识库问答系统的核心基础,它赋予了系统理解和处理人类语言的能力。在这个过程中,词法分析是第一步,它会将输入的文本拆分成一个个单词或词语,确定每个词的词性和词义。当系统接收到 “我喜欢苹果” 这句话时,词法分析会将其拆分为 “我”“喜欢”“苹果”,并识别出 “我” 是代词,“喜欢” 是动词,“苹果” 是名词。句法分析则是对句子的结构进行分析,确定各个词语之间的语法关系,比如 “我喜欢苹果” 中,“我” 是主语,“喜欢” 是谓语,“苹果” 是宾语。而语义理解是最为关键的环节,它需要结合上下文、语言习惯、语义知识库等,深入理解用户问题的真正意图。对于一些具有歧义的句子,如 “苹果掉到地上了” 和 “我喜欢吃苹果”,语义理解能够准确判断出两个 “苹果” 的不同含义。通过这些处理,将自然语言转化为计算机能够理解和处理的结构化表示,为后续的知识检索和答案生成奠定基础。
- 2.知识图谱与知识库:知识图谱是一种结构化的语义知识库,它以图形的方式展示了实体之间的关系。在知识图谱中,节点代表实体,如人、物、概念等,边则表示实体之间的关系,如 “属于”“拥有”“相关” 等。对于一个关于电影的知识图谱,“《泰坦尼克号》” 是一个实体节点,它与 “导演詹姆斯・卡梅隆”“主演莱昂纳多・迪卡普里奥”“凯特・温斯莱特” 等实体节点通过 “导演”“主演” 等关系边相连。知识库则是存储知识的地方,它可以是结构化的数据库,也可以是非结构化的文本库。系统在回答问题时,会首先在知识图谱中根据问题中的实体和关系进行检索,确定可能相关的知识范围,然后再从知识库中获取具体的知识内容。如果用户询问 “《泰坦尼克号》的主演是谁”,系统会在知识图谱中找到 “《泰坦尼克号》” 这个节点,通过 “主演” 关系边找到对应的主演实体,再从知识库中获取主演的详细信息,从而给出准确的答案。
- 3.答案生成与推理:答案生成是问答系统的最终目标,它需要根据知识检索的结果,运用合适的算法和策略生成自然语言形式的答案。基于模板的生成方法是较为简单直接的一种方式,它预先定义好一些问题模板和对应的答案模板,当系统识别出问题匹配某个模板时,就直接套用相应的答案模板生成答案。对于一些常见的固定问题,如 “一年有多少个月”,可以通过模板直接生成答案 “一年有 12 个月”。而基于深度学习的生成方法则更为智能和灵活,它通过大量的语料训练模型,让模型学习语言的生成模式和规律,从而能够根据问题和相关知识生成更加自然、准确的答案。在推理过程中,系统会运用逻辑推理、知识推理等方法,对获取的知识进行进一步的分析和推导,以得出更全面、准确的答案。当用户询问 “如果今天下雨,明天还会下雨吗”,系统可能会根据气象知识、历史数据等进行推理分析,给出一个合理的预测答案。
二、有哪些软件支持AI 知识库问答系统以及可行的AI交互界面?
1.1 FastGPT
定位:基于大语言模型的高效知识库问答系统,致力于为用户提供快速、准确的知识检索和问答服务。
主要功能:
- 1.数据处理:支持多种格式的数据导入,如文档、表格、网页等,并能自动进行数据清洗、分类和索引。
- 2.智能问答:利用先进的语义理解和检索技术,快速准确地回答用户问题,同时提供相关知识片段作为参考。
- 3.自定义配置:用户可根据自身需求,自定义问答逻辑、答案模板和界面样式。
对接 Ollama 思路:
- 1.在系统配置中,将 Ollama 作为语言生成的后端引擎,指定其运行地址和端口;
- 2.当用户提问时,FastGPT 先进行知识检索和预处理,然后将处理后的问题和相关上下文发送给 Ollama 进行回答生成。
适用场景:
- 1.企业内部客服系统,快速解答员工和客户的常见问题; 在线教育平台,为学生提供即时的知识答疑;
- 2.需要快速搭建高效知识库问答系统的各类组织和个人。
定位:智能高效的知识库管理工具,集文档编辑技术与人工智能技术于一体,旨在为用户打造便捷、智能的知识管理与问答环境。
主要功能:
- 1.多格式导入:支持 PDF、Word、Excel、PPT 等多种常见文档格式一键导入,快速整合知识资源。
- 2.智能搜索:融合基于 Elasticsearch 的关键词搜索与基于文本向量的 AI 搜索,能精准定位用户所需知识,无论是模糊语义理解还是精确关键词匹配都能应对自如。
- 3.AI 辅助功能:结合 ChatGPT 等 AI 工具,实现 AI 文档搜索,用户输入自然语言即可获取相关度高的文档内容;同时支持 AI 客服问答服务,模拟客服角色解答常见问题。
- 4.自定义配置:允许用户根据自身业务需求和使用习惯,对知识库的结构、权限、展示样式等进行自定义设置。
对接 Ollama 思路:
- 1.在 HelpLook 的系统设置或模型配置模块中,添加对 Ollama 的连接配置,填写 Ollama 本地服务的地址及端口。
- 2.当用户发起搜索或问答请求时,HelpLook 先按照自身的搜索逻辑筛选出相关知识片段,然后将这些片段和用户问题一同发送给 Ollama 进行深度的语义理解与回答生成,最后将结果呈现给用户。
适用场景:
- 1.企业知识管理,方便员工快速查找和利用内部资料,提升工作效率。
- 2.在线教育领域,教师可以整理课程资料形成知识库,供学生自主查询学习。
- 3.客服团队,快速搭建知识库,为客户提供准确、及时的问题解答。
1.3AnythingLLM

定位:将本地文档或数据源整合进一个可检索、可对话的知识库,让 AI 助手 “懂你” 的资料。
主要功能:
- 1.文档管理:将 PDF、Markdown、Word 等多格式文件索引进系统。
- 2.智能检索:可基于向量数据库搜索相关文档片段,并在聊天时自动引用。
- 3.界面 +API:既提供用户友好的前端管理界面,也能通过 API 与其他系统集成。
对接 Ollama 思路:
- 1.在配置文件或启动脚本中,将 “语言模型推理” 后端地址指定为 Ollama 的本地服务。
- 2.当用户发起提问时,AnythingLLM 会先做知识检索,再将检索到的上下文发送给 Ollama 做语言生成。
适用场景:
企业内部文档问答、个人知识管理、高度依赖文本内容的问答场景。
1.4Open-WebUI
定位:
- 社区驱动的网页版用户界面,针对多种本地模型提供可视化使用入口,类似一个 “本地 ChatGPT 面板”。
主要功能:
- 1.浏览器聊天界面:在局域网或本机通过网页即可与模型交互。
- 2.支持多后端:LLaMA、GPT-NeoX 等,以及 CPU/GPU 等不同推理环境。
- 3.插件/扩展机制:在社区里可找到各式各样的扩展功能(如多语言 UI、模型切换、对话模板等)。
对接 Ollama 思路:
- 1.通常可在 Open-WebUI 的后台配置或启动脚本中,指定 Ollama 作为推理后端;
- 2.或使用适配 Ollama 协议的插件,让 Open-WebUI 调用 Ollama 进行对话。
适用场景:
- 需要 “纯聊天 + 模型管理” 界面的普通用户或开发者;想要单纯体验各种本地模型的人群。
1.5MaxKB
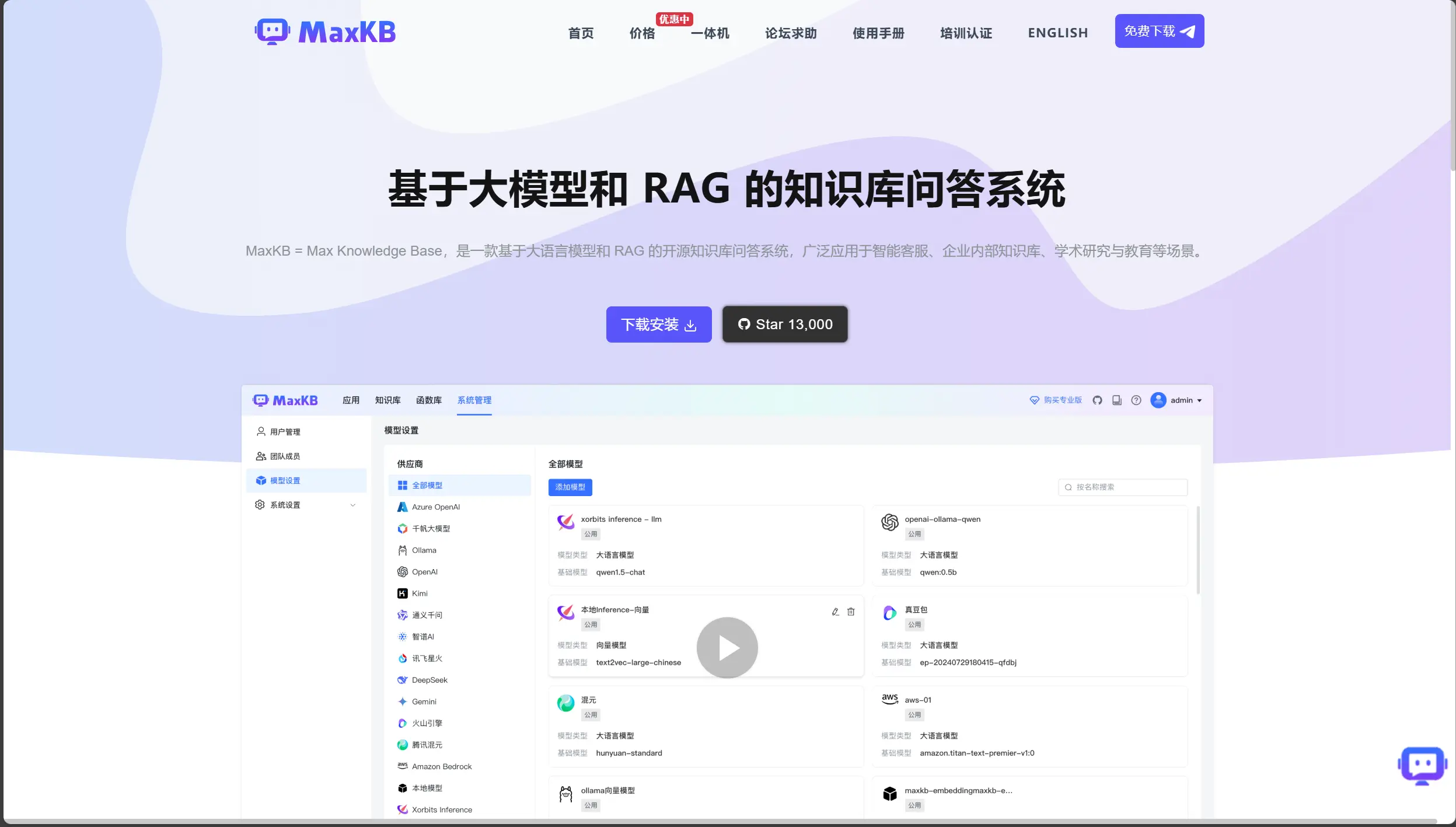
定位:
- 专注于基于大语言模型和 RAG(检索增强生成)的开源知识库问答系统,旨在为用户提供专业的学习能力和快速准确的问答响应。
主要功能:
- 1.文档上传与爬取:支持直接上传各类文档,如 PDF、DOCX 等,同时也能自动爬取在线文档,极大丰富知识库来源。
- 2.自动拆分与向量化:将上传或爬取的文本自动拆分成合适的片段,并转化为向量形式,便于高效检索与模型匹配。
- 3.零编码集成:能零编码快速嵌入到第三方业务系统,无论是网站、APP 还是其他应用程序,都能轻松集成,实现无缝对接。
- 4.多模型对接:支持对接各种大语言模型,包括但不限于开源模型和商业模型,用户可根据需求灵活选择。
对接 Ollama 思路:
- 1.在 MaxKB 的配置文件或后台管理界面中,明确指定 Ollama 为大语言模型服务端,设置好 Ollama 的本地访问路径。
- 2.当用户提问时,MaxKB 首先在本地知识库中进行向量检索,找到相关文本片段,然后将这些片段和问题传递给 Ollama,Ollama 依据接收到的信息生成回
- 3.答并返回给 MaxKB,最终呈现给用户。
适用场景:
- 1.企业内部知识问答场景,员工可以快速获取业务相关知识。
- 2.开发者希望在自有项目中快速集成知识库问答功能,且无需复杂编码工作。
- 3.学术研究机构整理和查询专业资料,辅助研究工作。
1.7Dify
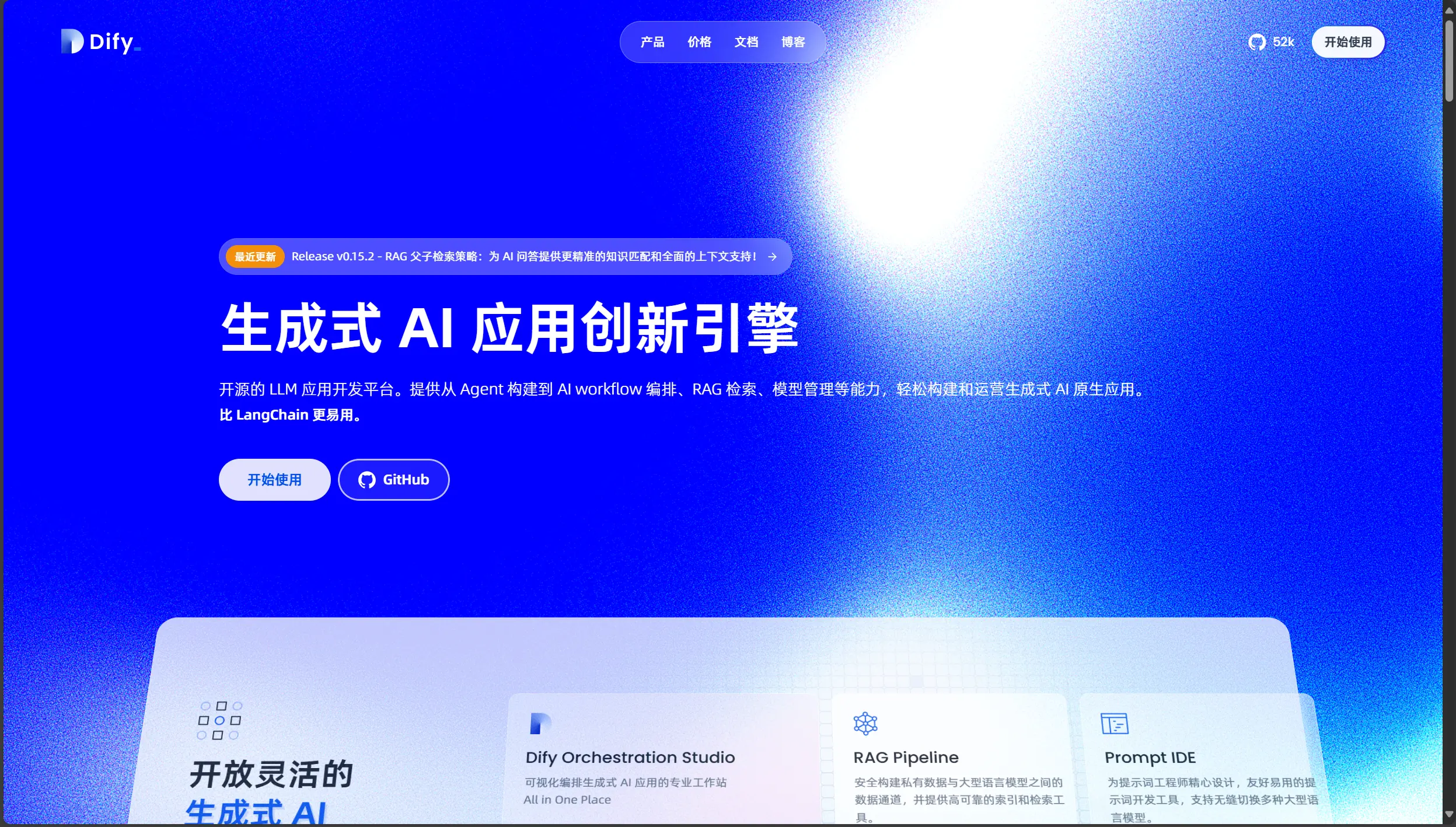
定位:
- 多功能的 AI 应用构建平台,支持多种大语言模型,方便开发者快速搭建 ChatGPT-like 服务或插件化应用。
主要功能:
- 1.对话管理:可自定义对话流或应用场景,为不同场景配置不同模型或工作流。
- 2.插件扩展:支持将其他第三方服务或插件加入对话流程中,提高可用性。
- 3.多模型兼容:除 Ollama 外,也兼容 OpenAI API、ChatGLM 等其他模型。
对接 Ollama 思路:
- 1.在 “模型管理” 或 “模型配置” 界面/文件中,添加对 Ollama 的引用,可能需要指定本地运行地址 (如 localhost:port)。
- 2.使用 Dify 的对话页面或 API 时,后台调用 Ollama 进行推理,再将结果返回前端。
适用场景:
- 1.多模型切换、多功能插件集成;需要可视化对话配置或工作流管理的团队与开发者。
以上是博主觉得比较常用的软件,后续会再度补充,欢迎大家指正错误或提出更多的相关软件~
感谢阅读~!
文章:Luminous辰汐
校对:萌即是正义! 雨落向晚亭

评论(1)